

There are a vast array of file systems available to use with the Linux kernel today but there are really only a few that see heavy usage from the Linux community. We’ll take a look at a few of the most popular file systems in use today as well as an up-and-coming file system that I’ve had my eye on for quite a while!
Extended File System, version 4 (ext4)
The ext4 file system is without a doubt the most popular choice for file storage in the Linux (especially, desktop) world. ext4 is the latest generation of the Extended File System family, with both ext2 and ext3 being used heavily prior (and even still today in some instances). Developed by long-time Linux kernel developer, Theodore Ts’o, ext4 was introduced as stable in October 2008, using speedy linked lists and hashed B-Trees as the base data structure.
ext4 is what is known as a journaling file system, which means that it uses a “journal” (usually a circular log) to record the intentions of changes that are not yet committed to the file system. This feature allows for users to retain data in the event of a crash or unexpected shutdown.
If you have installed a Linux distribution with the default settings in the installer, chances are extremely high that you’ve been using ext4 all along without even knowing it. This is because ext4 is the default file system for the vast majority of Linux distributions on the planet. Though even T’so himself has said that ext4 isn’t the future of file systems–those rights are reserved for the likes of Btrfs or ZFS–what functionalities ext4 lacks it more than makes up for in pure speed and reliability.
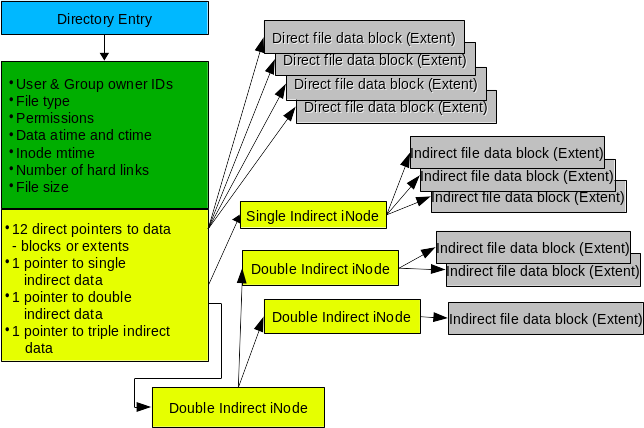
In the beginning, the early versions of Linux used a modified version of the MINIX 1 file system. However, the MINIX file system ran into a bunch of limitations and many of the early kernel developers had laid out plans to replace it very early on. The first attempt by T’so was the original Extended File System (ext). ext became the very first file system to utilize the Virtual File System (VFS) layer in the Linux kernel–which is an extremely important aspect of the kernel that allows so many different file systems to work with it.
However, the way that ext was built gave rise to a whole bunch of other issues compared to the MINIX file system. Though ext fixed the limitations of the MINIX file system, it contained other problems like the lack of support for separate timestamps according to file access, inode modification, or data modification.
In order to fix the problems with ext, T’so began working on ext2, which drew a lot of inspiration from the Berkeley Fast File System (also known as, the Unix File System or UFS), which was utilized in many different Unix and BSD operating systems (and still is today in the case of BSD). With these new improvements, ext2 quickly became a household name for early Linux adopters.
As the years rolled on, an extraordinary amount of work was put into the next iterations of the Extended File System family, ext3 and ext4. However, even with newer versions of the file system family, all three are still used in different situations today, though ext4 is recommended for most use cases. Today, ext4 is still the most popular Linux file system, even above more advanced kinds, like Btrfs or ZFS. I think it is pretty safe to say that this file system will be around for a very long time!
X File System (XFS)
Initially developed by yesteryear’s tech megalith, Silicon Graphics Inc. (SGI), XFS was originally conceived for SGI’s own commercial UNIX variant, IRIX, in 1993. The main goal? High performance, high reliability, and better parallel performance. As Linux began to gain enterprise clout throughout the 1990s, it was clear that SGI should make their file system available to the up-and-coming UNIX competitor. In 2003, XFS was ported to the Linux kernel by Steve Lord and saw its first inclusion into a Linux distribution in 2001. In mid-2002, Gentoo became the first distribution to allow XFS as the default file system through an option flag in the install process.
Today, XFS can be utilized in any flavor of Linux due to its integration in the mainline Linux kernel and remains one of the most actively developed file systems in the kernel. Like ext4, XFS is a journaling file system with a focus on speed due to parallel input/output operations–a feature based on allocation groups within its architecture. XFS also employs metadata journaling as well as write barriers in order to ensure the consistency of data held in the B+ Trees that make up its main indexing structure.
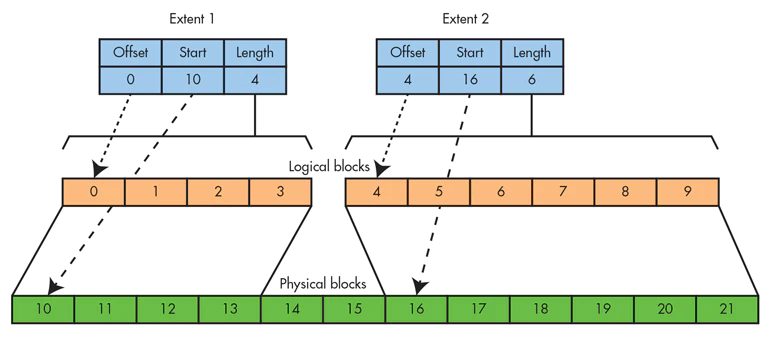
XFS has a large amount of developer support behind it and is utilized heavily in many areas of enterprise. Though it lacks the functionality of file systems like Btrfs and ZFS, the roadmap for XFS contains a lot of very exciting new features including snapshots, Copy-on-Write (CoW) data, data deduplication, reflink copies, online data and metadata scrubbing, accurate reporting of data loss and bad disk sectors, and significantly improved tooling for reconstruction of damaged or corrupted file systems.
This work is very difficult because in order to do it, the on-disk format of XFS must be changed, which is very difficult to do with backwards compatibility in mind. It will definitely be interesting to see how the XFS developers begin implementing these advanced features and if they will be able to keep up the speed and reliability that XFS has long been known for.
Z File System (ZFS)
Originally created by Sun Microsystems in 2006 via a team lead by Jeff Bonwick, ZFS is considered by many to have been the first of the “next generation” file systems, including advanced features like full file system snapshots, per-block checksumming, and self-healing properties. Originally coined as the “Zettabyte File System”, that name has been dropped in favor of the simpler “Z File System” moniker. Though ZFS was created as part of Sun Microsystem’s proprietary UNIX offering, Solaris, it would eventually make its way into the open-source world via the decision by Sun to open-source most of Solaris codebase, including ZFS, through the OpenSolaris project.
Unfortunately, with the acquisition of Sun by Oracle in 2010, OpenSolaris became closed source as well as the ZFS file system. Fortunately, engineers who had worked on Solaris and OpenSolaris kept the open-source code alive with initiatives like OpenIndiana and the illumos project. In order to coordinate and improve upon the last available ZFS code, a initiative known as OpenZFS was started and grew into a major hand in helping bring the possibilities of ZFS to other operating systems besides OpenIndiana. The very strong initiative by the OpenZFS developers to bring ZFS to the Linux kernel birthed the now-popular ZFS on Linux (ZoL) codebase.
Now, unlike the other file systems on this list, ZoL is actually not provided as part of the mainline Linux kernel. This is due to the CDDL license that Sun Microsystems used to open-source Solaris and its unfortunate incompatibility with the Linux kernel’s GPLv2 license. Considering that Oracle, a long-time enemy of the open-source movement (which have been known to litigate), has the rights to the proprietary ZFS file system, Linus himself has stated that ZFS will never be integrated into the mainline kernel barring written consent from Oracle’s CEO.
Even so, the OpenZFS project maintains the ZoL project, which allows Linux users who want to leverage ZFS do so by incorporating it into the kernel via a DKMS (Dynamic Kernel Module Support) module. Though, this isn’t recommended for new Linux users, there are many threads on the topic just in case you’d like to see what ZFS has to offer on your Linux distribution.
More recently, ZoL support became an experimental feature integrated into the installer of Canonical‘s Ubuntu, the most popular and widely used desktop Linux system in the world, with the 19.10 “Eoan Ermine” release. Though many questions have been raised about the true legality of this inclusion, Canonical has publicly stated that they have had some of the top experts in software law review the possible case for utilizing ZoL and have said that they cannot see any way that it could be used against them by Oracle or anyone else for that matter.
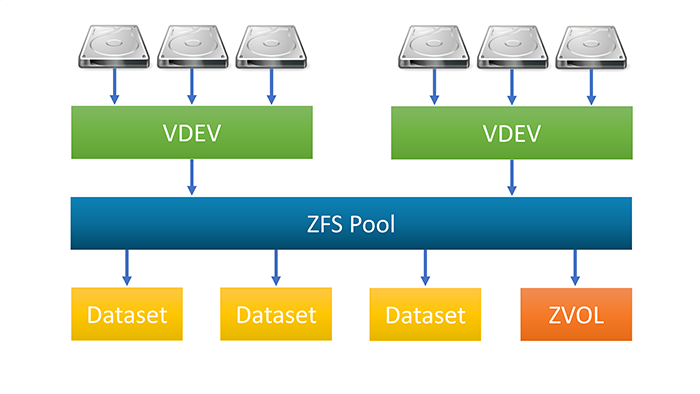
The main advantages of ZFS include pooled storage for integrated volume management, copy-on-write data and metadata, snapshots, data integrity verification, self-healing properties, RAID-Z configurations, internal compression, end-to-end checksumming, a massive maximum file size (16 Exabytes) and total storage size (256 Quadrillion Zettabytes), as well as no limit to the number of datasets or files available among other advanced features.
ZFS is a massive codebase with an incredible history of robustness and innovation behind it. Unfortunately, the licensing issues surrounding it will hold it back from mainline adoption, but it is still at the heart of many enterprise based storage solutions today. In fact, the most popular Network Attached Storage (NAS) operating system in the world, FreeNAS (now TrueNAS CORE) utilizes OpenZFS with a stripped down version of FreeBSD.

B-Tree File System (Btrfs)
A proposition by Ohad Rodeh at The Advanced Computing Systems Association (USENIX) in 2007, brought the CoW (Copy-on-Write) B+ Tree data structure into public attention. Though the b-tree data structure was originally created over 45 years ago (in 1975) and has gained considerable use in computer science since, the CoW aspects of this novel implementation sparked the idea of a new file system built around it in the mind of SUSE employee, Chris Mason, who had been working on their ReiserFS project for some time.
Mason left SUSE for Oracle to begin building Btrfs (often pronounced “Butter FS” or “Better FS”) as a possible open-source replacement next generation file system to rival the popular and extremely advanced ZFS. The goal of Btrfs was stated by Mason in the early days of development:
“[The goal was] to let [Linux] scale for the storage that will be available. Scaling is not just about addressing the storage, but also means being able to administer and manage it with a clean interface that lets people see what’s being used and makes it more reliable.“
Therefore, Btrfs has constantly attempted to achieve “feature parity” with its main competitor, ZFS. Btrfs includes many of the favorable features found in ZFS, with a few of it’s own including being an extent-based file system, dynamic node allocation, writeable snapshots, subvolume integration, checksumming on data and metadata, internal compression, integrated multiple device support, incremental backup, self-healing properties, out-of-band deduplication, swapfile support, SSD (flash storage) awareness, and offiline file system checks among other advanced features.
It took two years for Btrfs to be accepted into the mainline Linux kernel after finalizing its on-disk format. In its earliest years, Btrfs was plagued by bugs and was not considered a reliable file system to use. However, many major open-source companies saw the potential of having a next generation file system that could match ZFS and Btrfs really started gaining momentum from the likes of SUSE, Oracle, Red Hat, and, more recently, Facebook. Due to this enterprise backing, Btrfs began to develop extremely quickly and looked to soon become the default file system for Linux.
However, as Btrfs grew, more and more problems were found in its underlying architecture, and just as it was supposed to be ready for prime time in around 2015, it was clear that much more work was needed before it could be claimed reliable. The Linux community became split on Btrfs, with Red Hat deciding to remove it from their flagship Red Hat Enterprise Linux 8 release. On the other hand, SUSE adopted Btrfs as its default file system in their flagship offering, SUSE Linux Enterprise Server, as well as the community-run open-source implementation, openSUSE.
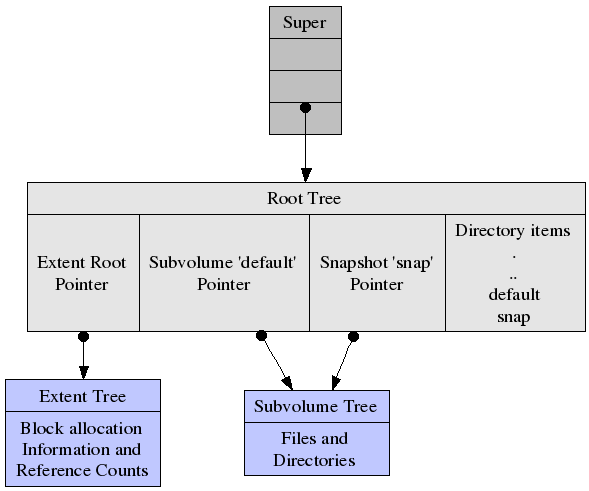
Today, there is no doubt that Btrfs has advanced incredibly since that time of uncertainty. SUSE has been working on the project as well as using it as the default file system option for going on five years. Facebook, a company that ingests a massive amount of data each and every day has chosen Btrfs as their storage file system. And, more recently, the Fedora community has shown its support for Btrfs by voting on the use of it as the default file system in Fedora 33 in place of ext4.
I think it is safe to say that Btrfs will grow in adoption more and more over the years as the major Linux companies begin throwing their weight behind it (as with many other components like systemd or Wayland). With the addition of Btrfs as Fedora’s default file system, we may even see it creep in as the default in RHEL 9, when that is launched. It is definitely an exciting time for the Btrfs team and I know I am looking forward to seeing the potential and possibilities that it will provide as intensive development continues.

Block Cache File System (bcachefs)
In 2015, Linux kernel developer, Kent Overstreet, announced a project that he had been working on for some time–a new filesystem named Bcachefs. Built upon a cache structure in the Linux kernel’s block layer, bcache, the goal of the project is to provide a file system that includes many of the advanced features of next generation file systems, like Btrfs and ZFS, while keeping competitive performance of more stripped down file systems, like ext4 and XFS.
Though the project is still young (it only has 5 years of development behind it as opposed to 14 and 13 years for ZFS and Btrfs, respectively), Bcachefs has shown some extremely promising results early on. At the moment, Bcachefs is not part of the mainline Linux kernel, but according to Overstreet, it is very close to hitting that goal in the near future. Recent testing by community members like Michael Larabel (Phoronix) have shown that Bcachefs has very promising results when compared to the other popular Linux file systems, however, not all features have been implemented in their entirety. The advanced features that will make their way into Bcachefs include:
- Copy-on-Write (CoW)
- Full data and metadata checksumming
- Multiple devices, including other types of RAID
- Caching
- Compression
- Encryption
- Snapshots
- Scalability
- Erasure Coding and much more
It is safe to say that Bcachefs is an extremely intriguing up-and-comer with a solid foundation and extremely well thought-out design that boasts one of the cleaner codebases (though it is still young ;)) out of all the file systems. Bcachefs is currently being developed primarily by Overstreet, who left his career at Google to work on the file system full-time, with the help of a few developers as well as a small, but dedicated group of testers. Because Overstreet is working on Bcachefs full-time, the project is funded by his Patreon page that can be found here.
Personally, I can’t wait for Bcachefs to be merged into the mainline kernel to make it easier to test and utilize. I hope to see this advanced file system make a name for itself in the coming years and become a major competitor to other next generation file systems like Btrfs and ZFS.
Of course, there are many other file systems supported by the Linux kernel including JFS, ReiserFS, 9p, AFS, BFS, FUSE, RamFS, F2FS, and even Microsoft’s exFAT and NTFS file systems, however, the above are the most commonly seen in the Linux world.
